Function descriptions
Indexer - PurposeChain
The PurposeChain uses several extensible factors to determine whether a full-purpose index of an index
should get executed.
- By default, the following algorithms defined with DI, are executed as follows:
<!-- Default definition of the chain pattern for reindex purposes di.xml →
<type name="TechDivision\PacemakerIndexer\Model\ForceReindex\ReindexPurposeChain">
<arguments>
<argument name="purposes" xsi:type="array">
<item name="onsave" xsi:type="object">
TechDivision\PacemakerIndexer\Model\ForceReindex\OnSavePurpose
</item>
<item name="threshold" xsi:type="object">
TechDivision\PacemakerIndexer\Model\ForceReindex\ThresholdPurpose
</item>
<item name="reindex_required" xsi:type="object">
TechDivision\PacemakerIndexer\Model\ForceReindexRequiredPurpose
</item>
</argument>
</arguments>
</type>-
Additional Purposes can get registered with DI
-
This requires that the class implements the
ReindexPurposeInterfaceand rely on theBasePurposeclass
-
The PurposeChain gets used in the IndexerForceReindexExecutor and checks each index passed to the
step to see if it needs to get updated with the Full Reindex.
OnSavePurpose
The OnSavePurpose checks whether the index passed to it is ON SAVE.
If ON SAVE, a full reindex gets triggered for the index within the IndexerForceReindexExecutor.
|
We recommended the check because the Pacemaker import does not start any triggers in the database; therefore, a product save does not result in an index update. It ensures that even though there is a misconfiguration in the indexers with relation to Pacemaker, the index gets updated. |
ThresholdPurpose
The ThresholdPurpose checks the delta/diffs of the passed index.
-
If the delta is greater than the configured threshold of the indexer, a full reindex is executed
-
The check provides an enormous performance benefit since it is often faster (e.g., after a product import) to regenerate the complete index instead of resolving the deltas
-
The configuration should always take into account the maximum import data count as well as the product count of the shop
ReindexRequiredPurpose
The ReindexRequiredPurpose cleans up an invalid index and rebuilds the index.
-
If an index has the status REINDEX REQUIRED, it gets regenerated with Full-Reindex
-
This is a backup mechanism to clean up indexes without manual interaction
|
An indexer with the status REINDEX REQUIRED must be cleaned manually (without Pacemaker indexer) with the
CLI command |
Media Cache Updates
Pacemaker Import Pipelines allows you to import images and videos through the Catalog Import Pipeline or the dedicated Media Import Pipeline.
-
The media files must get physically stored on the server, and Magento’s media gallery must get prepared with the CLI command.
-
The Configuration settings can be used to define how the image cache gets handled after an import
CleanUp
After a media import, the Media Cache Cleanup step invalidates the cache of images by default.
-
This ensures that after an import, e.g., when a product detail page gets called, the image cache is regenerated, and the new images are requested again within Magento
-
The executor of the step checks the configuration and invalidates the cache and the images, which are also invalid when imported
Refresh
The refresh step is disabled by default and can be enabled through the configuration if required.
-
Instead of just invalidating the cache, the step can get used to recreate the entire media cache instead of requesting and caching the required image on each new page load
-
The executor of the step checks the configuration and calls the Magento CLI command
bin/magento catalog:images:resize
ImportExecutor
The ImportExecutor is a main component of the import pipelines.
-
It has been implemented specifically to call the Importer functionality in the process pipeline context
-
The
ImportExecutorchecks the import binary and executes it with the CLI command -
The parameters of the CLI command can be adjusted with arguments to control the desired imports with the necessary parameters
vendor/techdivision/pacemaker-import-base/Model/Executor/ImportExecutor.php<?php
private
function runImport(StepInterface $step): void
{
$newFileName = '';
if ($step->getArgumentValueByKey('single_mode')) {
$files = $step->getArgumentValueByKey('files');
$workingDir = $step->getArgumentValueByKey('_working_directory');
$newFileName = $workingDir . '/' . basename($files[0]);
}
// initialize the command with the executable, the command and the operation name
$command = [
$this->getExecutable($step),
$step->getArgumentValueByKey('command'),
$step->getArgumentValueByKey('operation'),
$newFileName
];
// finally, invoke the command
$this->runCmd(array_merge($command, $this->renderOptions($step), ['2>&1']));
}vendor/techdivision/pacemaker-import-media/etc/pipeline.xml<step name="media_import" executorType="TechDivision\PacemakerImportBase\Model\Executor\ImportExecutor" sortOrder="40" description="Import media"
>
<conditions>
. . .
</conditions>
<arguments>
<argument key="command" value="import:products:media" />
<argument key="operation" value="add-update" />
</arguments>
</step>ImportFilesDataFetcher
The ImportFilesDataFetcher is the heart of the import pipelines.
-
It connects the import configurations to the Process Pipelines system through AOP and registers the defined import pipelines in the pipeline initializer
-
It determines which files are processed configurative in which pipeline
-
The registration to the pipeline initializer takes place with DI
/vendor/techdivision/pacemaker-import-base/etc/di.xml<type name="TechDivision\PacemakerPipelineInitializer\Model\InitializationDataFetcherChain">
<arguments>
<argument name="dataFetcher" xsi:type="array">
<item name="pacemaker.import.files.resolver" xsi:type="object">
TechDivision\PacemakerImportBase\Model\ImportFilesDataFetcher
</item>
</argument>
</arguments>
</type>-
The
ImportFilesDataFetchercan be extended through DI -
For each import pipeline, this must be expanded to import or process the correct files in the desired pipeline
- The following information must be transferred:
-
-
The configuration path, if the import pipeline is active
-
The pipeline name, according to XML definition is correct
-
Bunch resolver, modification of
ImportBunchResolverto read and process the correct files -
A bunch validator to generate the pipeline only when everything is ready to go
-
An OK file must be present as standard
-
vendor/techdivision/pacemaker-import-media/etc/di.xml<type name="TechDivision\PacemakerImportBase\Model\ImportFilesDataFetcher">
<arguments>
<argument name="resolverConfig" xsi:type="array">
<item name="pacemaker.import.media" xsi:type="array">
<item name="resolver" xsi:type="object">
TechDivision\PacemakerImportMedia\Virtual\ImportBunchResolver
</item>
<item name="validator" xsi:type="object">
TechDivision\PacemakerImportBase\Api\ImportBunchValidatorInterface
</item>
<item name="pipeline_name" xsi:type="string">
pacemaker_import_media
</item>
<item name="enable_config_path" xsi:type="string">
techdivision_pacemaker_import/media/enabled
</item>
</item>
</argument>
</arguments>
</type>ImportBunches
Import bunches are bundled import files that are processed through a pipeline.
-
ImportBunches must be determined through the
ImportBunchResolverand checked by the << ImportBunchValidator, 19>>. -
The import files are subject to the following scheme
-
import-<TYPE>>_<IDENTIFIER>>_<COUNTER>>.csv
-
-
There must also be an OK file with the following schema
-
import-<TYPE>>_<IDENTIFIER>>.ok
-
ImportBunchResolver
The ImportBunchResolver summarizes the dropped files based on type and identifier.
-
Depending on the number of bunches, the following pipelines are generated
-
The type is passed from the
ImportFilesDataFetcherbased on the existing pattern and determined
Enhancement / Adaptation Import Pro Component
- To enable import with Pacemaker process pipelines of uploaded files were:
-
-
Adjusted areas of the import GUI
-
A connection of the cron logic to the pipeline logic gets established
-
Classes Overlay
All import GUI-defined classes are overwritten with DI to ensure the processing of imports with pipelines.
/vendor/techdivision/pacemaker-import/etc/di.xml<preference for="TechDivision\ImportGui\Controller\Adminhtml\Index\CreateOkFile" type="TechDivision\PacemakerImport\Controller\Adminhtml\Index\CreateOkFile"/>
<preference for="TechDivision\ImportGui\Model\CreateOkFile" type="TechDivision\PacemakerImport\Model\CreateOkFile"/>
<preference for="TechDivision\ImportGui\Model\FilesUploader" type="TechDivision\PacemakerImport\Model\FilesUploader"/>
<preference for="TechDivision\ImportGui\Model\M2IF" type="TechDivision\PacemakerImport\Model\M2IF"/>Provider
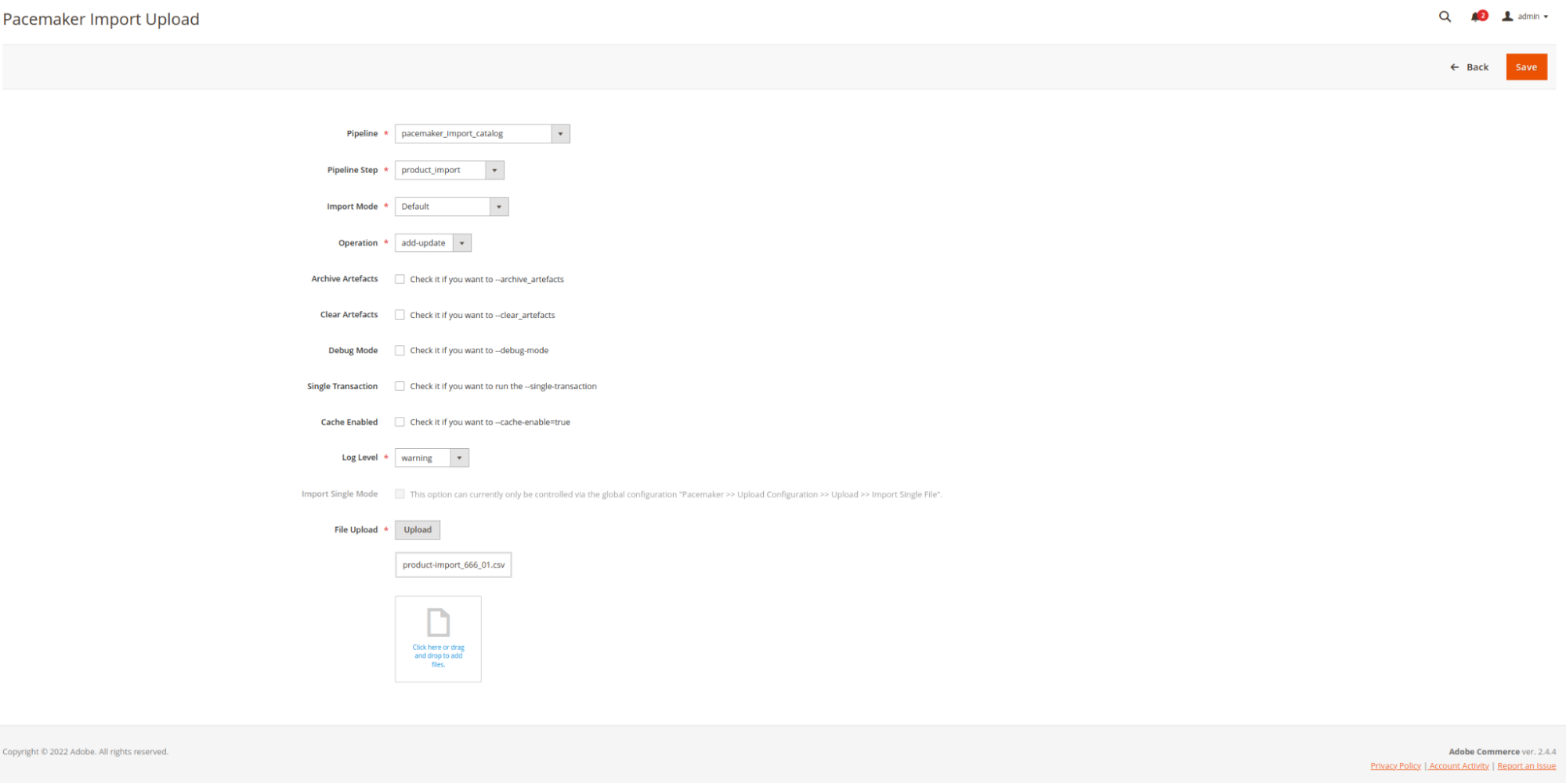
To define which pipelines with which steps are intended for processing, pipelines must get recognized.
-
Pipeline identification is made automatically by the pipeline provider
-
The pipeline provider determines all available pipelines that contain an
ImportExecutoras a step executor
<?php
public function getPipelines(): array
{
$pipelineList = $this->config->getList();
// initialize pipelines
$pipelines = [];
foreach ($pipelineList as $item) {
if (!isset($item['steps'], $item['name'])) {
continue;
}
foreach ($item['steps'] as $step) {
if (!isset($step['executorType'])) {
continue;
}
if ($this->isImportExecutor($step['executorType'])) {
$pipelines[$item['name']] = $item['name'];
break;
}
}
}
return $pipelines;
}Attachment OK-File
In the import GUI, the action dynamically generates an OK file for processing through pipelines.
-
The pipeline defined in question is not created until the associated files, including OK are available
Link to the processing step
With the import GUI, a link to the processing step is provided through the action.
-
As soon as the import is processed, the created link is available in the import GUI overview
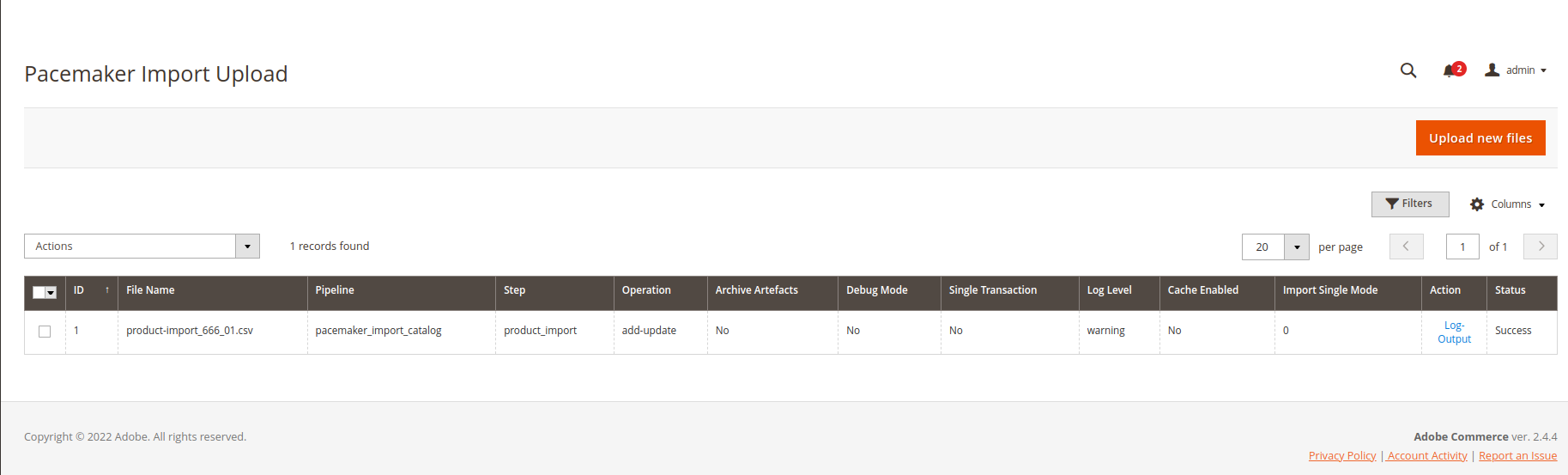
Validation
In the pipeline backend, there is an option to view the validation of the import framework.
-
The validation option
-
Provides a brief overview of import errors that occur
-
Is only present in the event of errors occurring
-
Validation Import Pipeline
In the Magento backend, you can create a validation import pipeline that separates the validation logic from the importer process. The advantage of this approach is that it allows you to run the validation without making any changes to the database. This ensures data integrity and helps identify errors or inconsistencies before committing to any updates.
Catalog Move Step
-
After installation the module
pacemaker-import-catalog-moveprovide the following functionality:-
Creation of a new category attribute
pacemaker_unique_id -
Extending the Catalog-Import-Piepline with two steps
-
transfrom_move_categories- Identify categories to move based on the csv data and write the file "move_category.json" -
move_category- Move the provided categories in file "move_category.json"
-
-
-
User Manual
-
For an example please use the provided import csv files in this module
-
It is necessary that all categories have a value for the attribute pacemaker_unique_id.
-
This attribute is the only way to control the move via Pacemaker in the category tree.
-
To move a category you need to provide the
pac_parent_idin the csv. -
Please note that the
pathandnamehave to match to the current path and name of the category as the "source". -
With the
pac_parent_idyou define the "destination". -
If the path and/or name does not match with the current structure a new category will be generated (default import behaviour)
-