Setup
- To run import pipelines, you must:
-
-
Set the relevant configurations
-
The infrastructure of the process pipelines (consumer/heartbeat) are activated
-
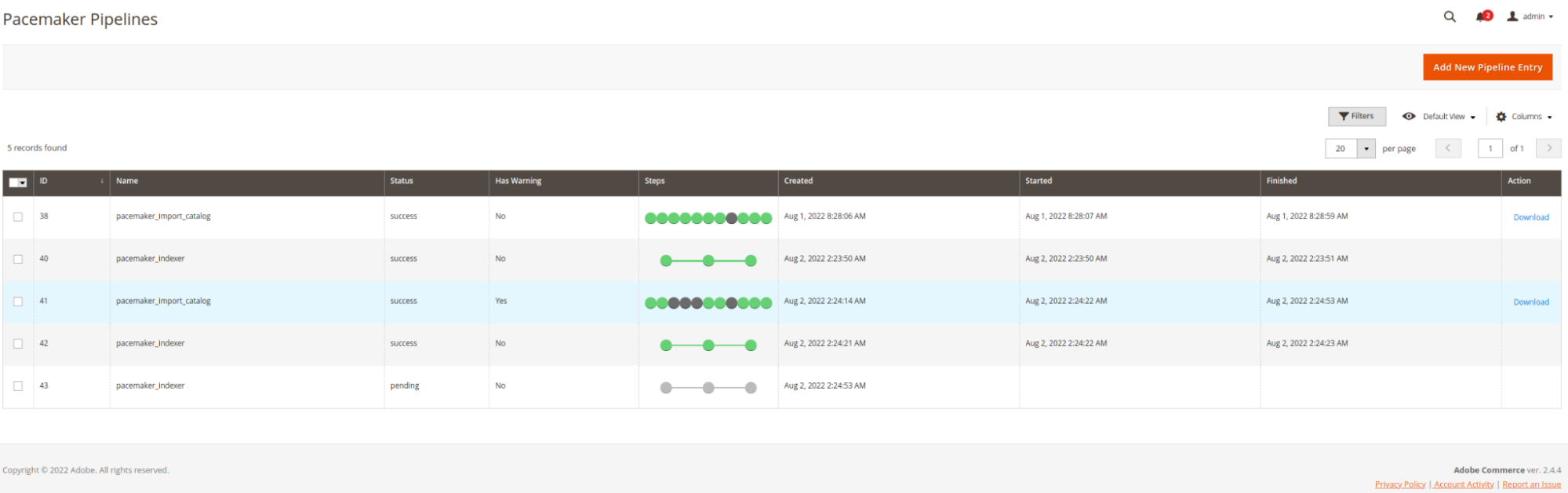
Automatic Standard Jobs
Pacemaker Indexer
After installing Import Pipelines, the Process Pipelines infrastructure is ready to run, and a Pacemaker indexer gets executed with each heartbeat.
Media Gallery initialization
|
To ensure that images appear correctly in the shop after imports and that image cache management works, the media gallery must be initialized or synchronized. Run the Pacemaker CLI command once after installation/updates (and again if necessary): Notes:
|
Import
File storage
- The following steps must get completed to perform an import through the file system:
-
-
Determination of the import directory
-
It is adjustable in the configuration.
-
-
Storage of valid import files in the defined directory
-
The file names of the structure name must correspond to the configuration
-
-
Creation of import OK files
-
Import OK files must follow the naming conventions of the configuration
-
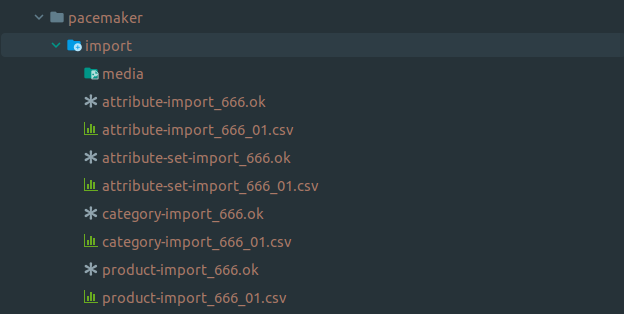
Please note the identifier
666and the counter for the CSV import files -
The identifier
666serves as an example and may only contain the characters defined in the configuration -
The standard are lowercase letters
a-z, numbers from0-9, and a hyphen- -
All files with the same identifier are combined into one pipeline if possible
-
-
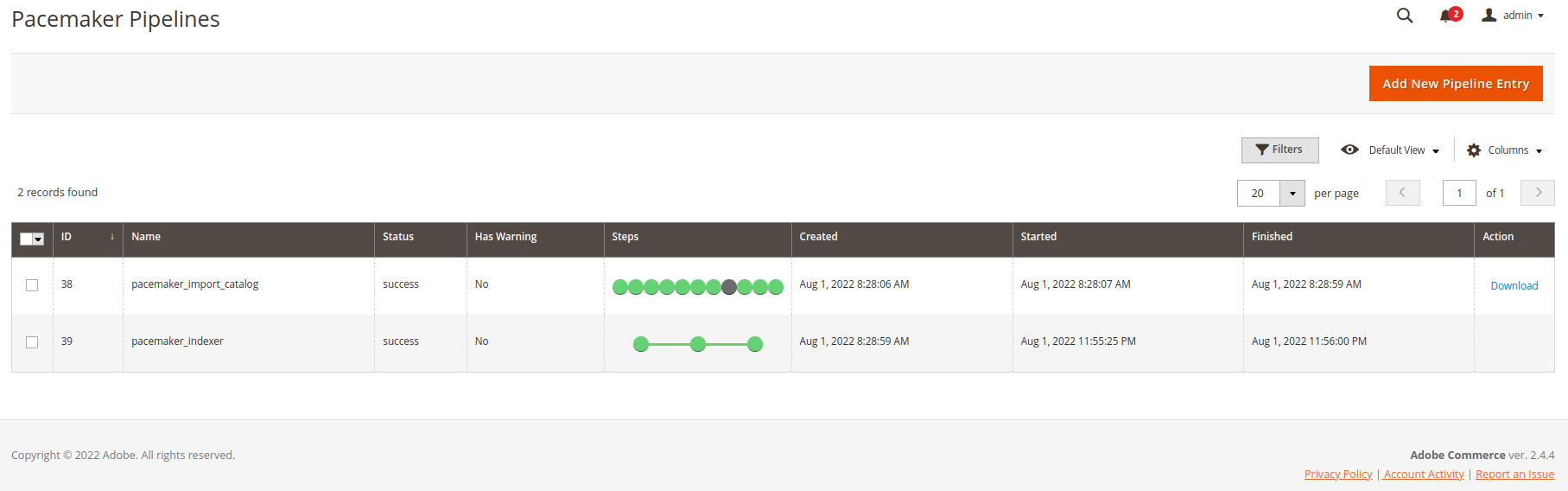
When a heartbeat gets executed, an import pipeline is created based on the existing files and depending on the naming convention (RegExp). All further heartbeats now execute the pipeline steps
-
As the first pipeline step, the files get moved to the working pipeline directory to work with these files
-
All further pipeline steps now work with this pipeline directory to process the files, create import artifacts, and write log information
-
-
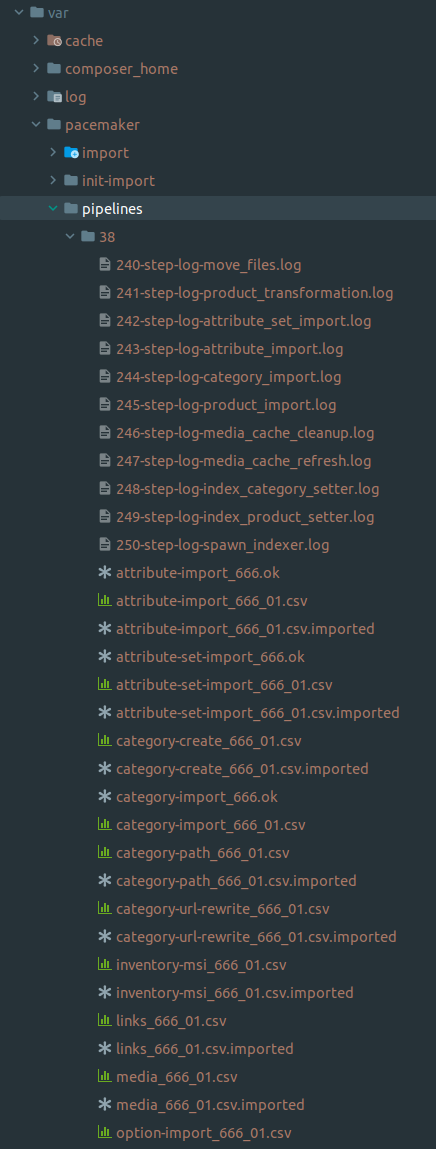
In addition to importing data such as
attributes,categories, andproducts, all necessary steps get initiated-
To keep and display the data correctly in the shop
-
Cleanup and creation of the media cache (see Media Gallery initialization)
-
Storage of the required index operations
-
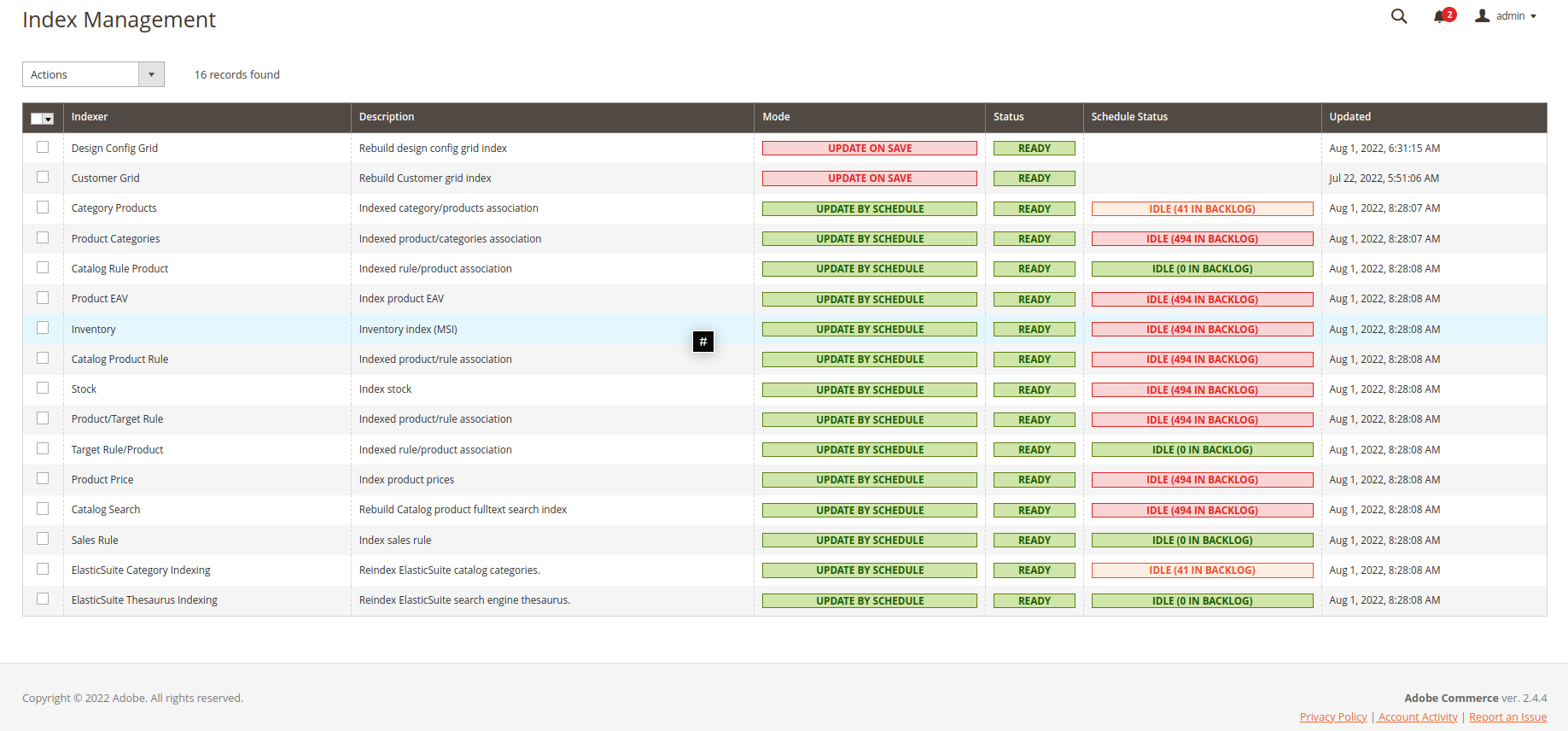
Creation of a Pacemaker Indexer Pipeline
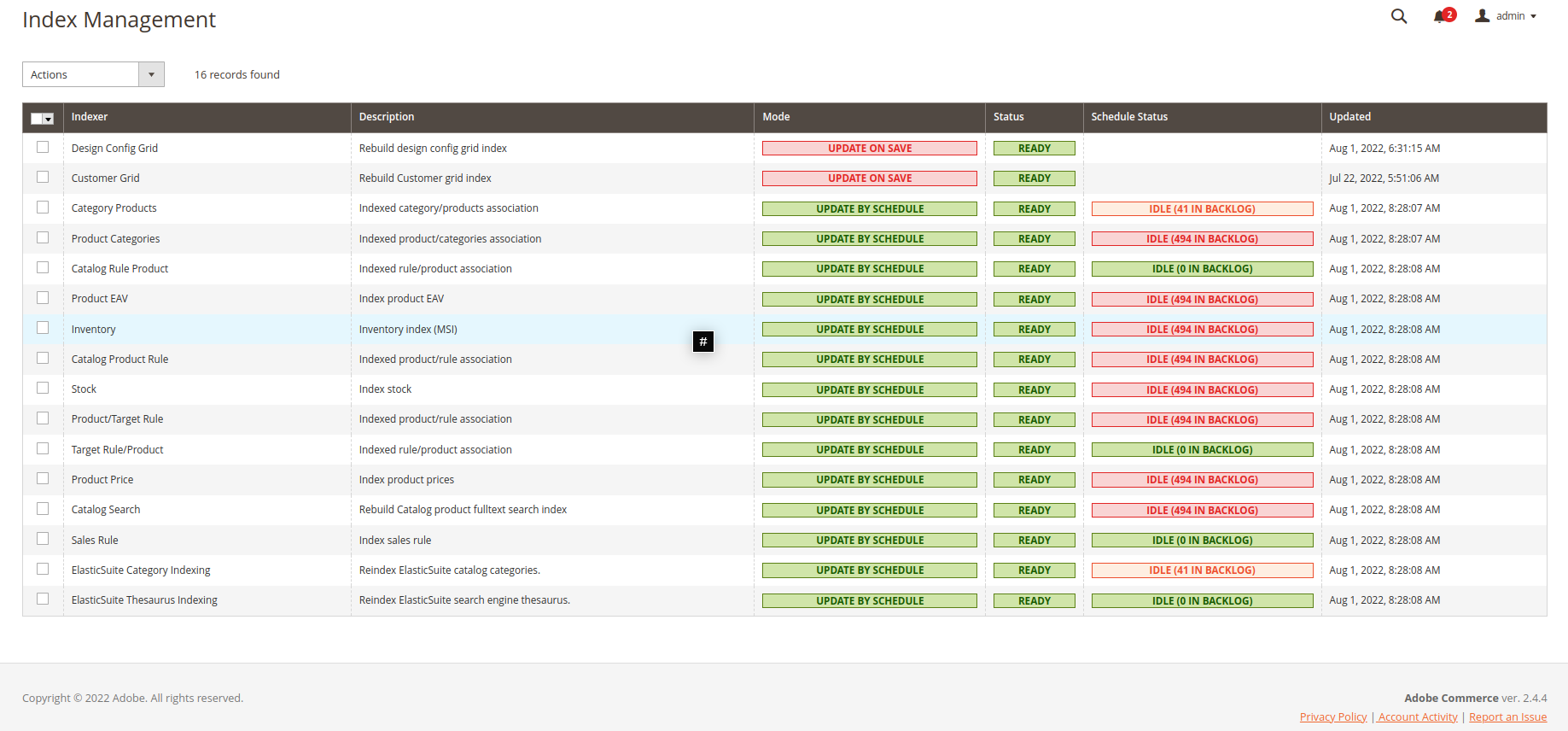
-
-
After the end of the following index pipeline, the products are available in the shop
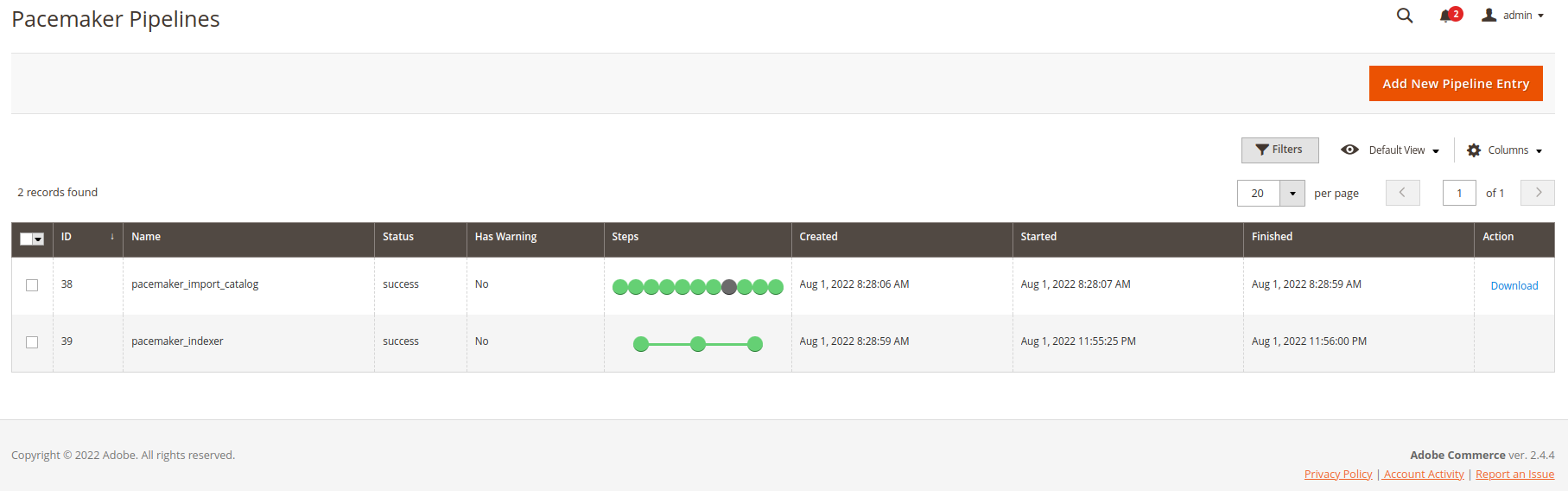
-
The import pipeline steps and the possible adjustments get described as follows
-
Backend file upload
In addition to the direct storage and processing of files, Import Pipelines offer the possibility to upload import files through the Magento backend and then process them further.
-
Under
the overview of all uploaded import files appears Import files can get uploaded
through the Upload new files button-
It can get defined with which parameters and in which pipeline context the import should get performed.
-
In the following setup example, a product import with standard parameters gets carried out through the
pacemaker_import_catalogpipeline
-
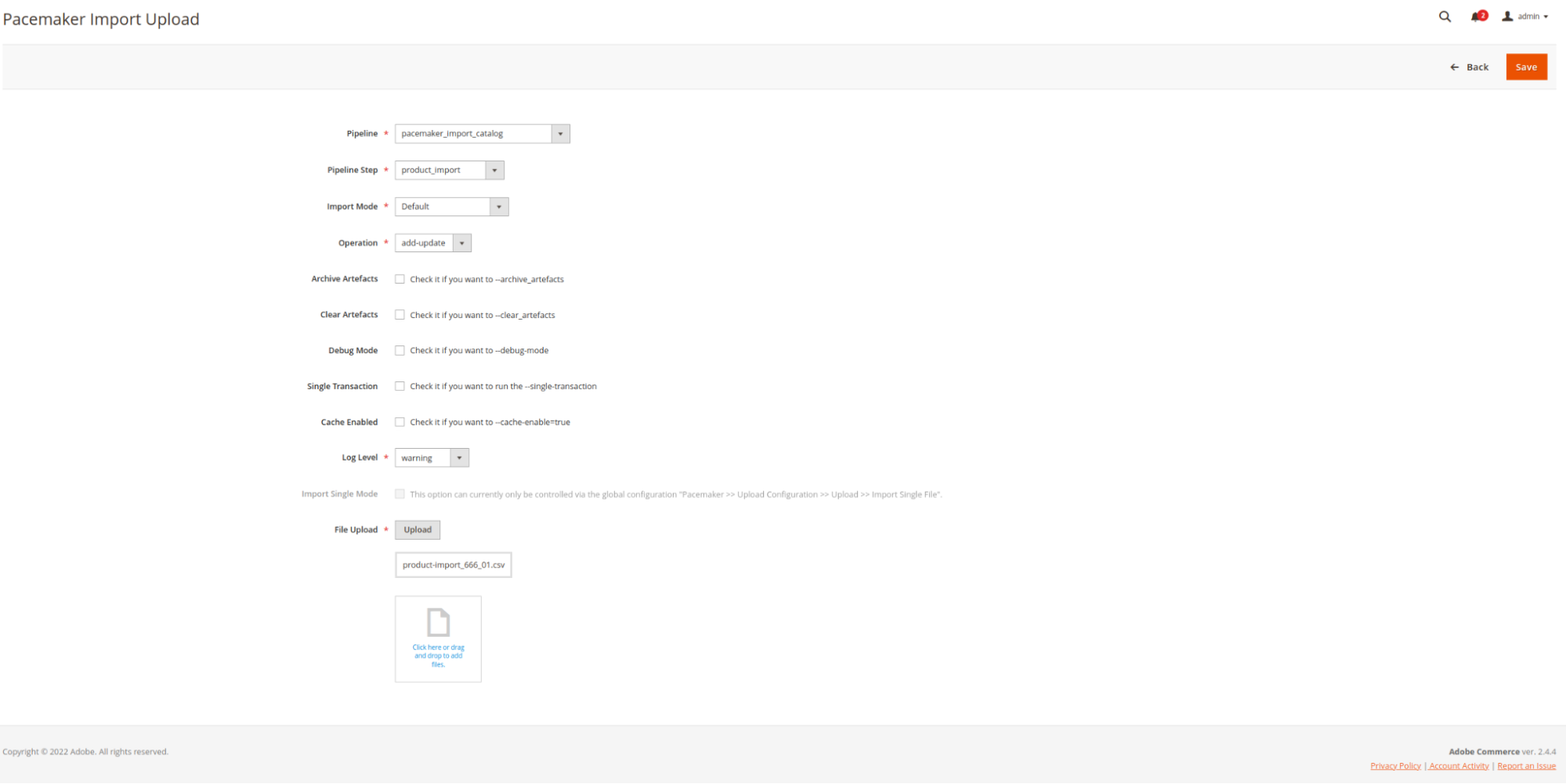
-
The new import upload gets then displayed in the view
-
With the action OK (in the table), an OK file generates
-
-
After the generation of the OK file, the import gets started
-
The selected import pipeline gets generated and processed with the configured heartbeat
-
Since only products are to get imported, all further import steps, such as attributes, are skipped
-